论文:OW-Adapter:Human-Assisted Open-World Object Detection with a Few Examples
作者:Suphanut Jamonnak, Jiajing Guo, Wenbin He, Liang Gou, and Liu Ren
发表:IEEE VIS 2023
开放世界目标检测(OWOD)作为一个新兴的计算机视觉问题,它不仅涉及到识别预定义的对象类,同时检测新出现的未知对象。现已有的几种端到端深度学习模型面临着几个挑战:(a)需要对网络架构和训练过程进行重大更改;(b)它们是从头开始训练的,无法利用现有的预训练通用目标检测器;(c)需要花大量的人工对所有未知类进行注释。为克服这些挑战,作者提出了一个可视化的分析框架,称为OW-Adapter。它充当适配器,使预训练的一般目标检测器能够处理OWOD问题。
背景介绍
开放世界对象检测(OWOD)是机器学习中一个新兴的视觉任务,机器学习模型的目标不仅是检测预定义的已知对象类别,还同时检测未知对象类别。传统上,一般目标检测器被训练为检测在训练数据中预定义的已知对象类别,例如图中所示的汽车、人。然而,它有时会将未知对象检测为预定义类别,并且具有较高的置信度分数,例如,把路上没见过的动物当成汽车。这限制了它在许多安全关键领域的应用,例如在自主驾驶中,自主车辆可能需要识别道路上的未知物体或障碍物(诸如道路碎片或动物)并适当地做出响应。因此,OWOD通过考虑在训练阶段遇到先前未见过的对象类的可能性来处理未知情况,OWOD检测器的主要任务包括:(a)像一般检测器那样准确地检测和识别已知类别;(b)从背景中识别潜在的未知对象;(c)对未知对象进行标注并微调模型以扩展其检测新类别的能力。
本文的贡献有三点:
- 第一个可视化分析框架,适应对象检测器处理OWOD问题
- 设计了一个可视化分析系统,以识别、总结、最少的人工在回路中注释未知对象
- 实验证明了适配器方法的有效性,该适配器方法可以提高预处理器的学习能力和检测性能。
相关工作
- Open-Set Recognition
- LOpen-World Object Detection
- Visual Analytic for XAI
- Visual Analytic for OOD Detection
算法设计
作者提出的方法的训练过程和推理过程如图所示:
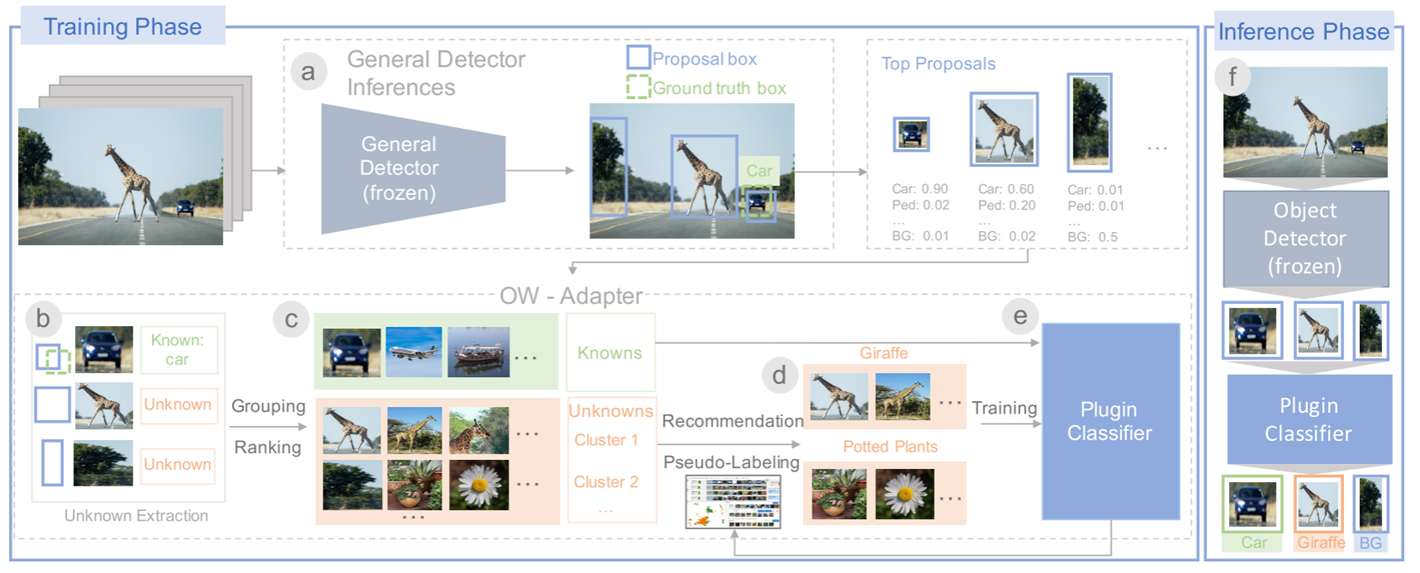
训练过程:
(a)首先从一个预先训练好的通用目标检测器开始
(b)提取潜在对象的候选框
(c)将候选框分组为不同的簇,并对簇进行排序,以便用户可以有效地识别潜在的未知类
(d)找到数据集中与该新发现的未知类同类被遗漏的候选框供用户注释
(e)使用新添加的标注训练一个轻量级分类器
推理过程:
(f)分类器作为插件加入到预先训练的模型进行推理
Unknown Extraction
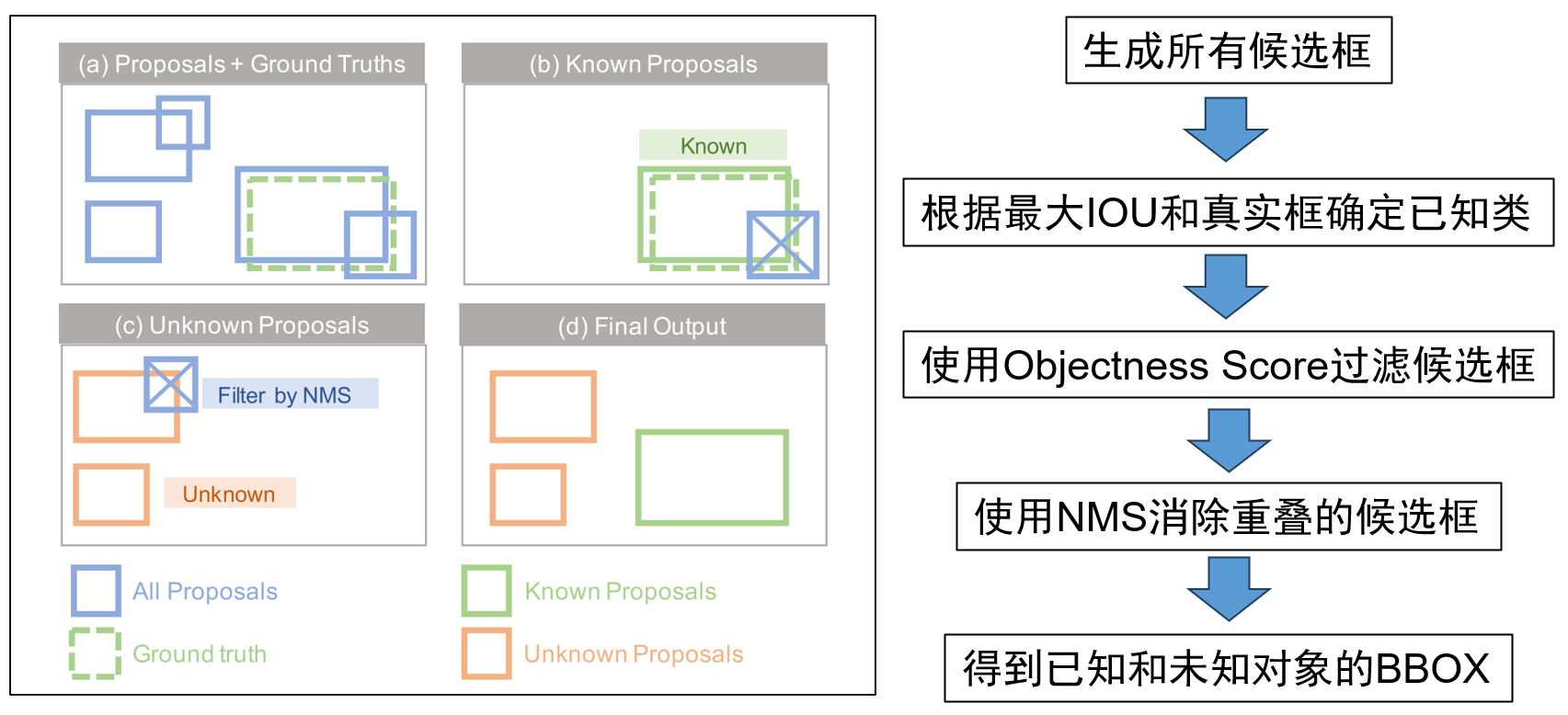
(a)先给定一个预先训练的目标检测器和一组输入图像,提取潜在的已知和未知对象。作者首先使用检测器来生成一组候选框,然后将这些候选框分为已知和未知两组。
(b)已知的组包含属于已知类的候选框,这些候选框与真实框重叠。对于与同一个真实框重叠的候选框,仅保留与真实框交并比最大的候选框。对于不与任何真实框重叠的候选框,将其视为潜在的未知对象。然后使用objectness score来过滤候选框,objectness score用于衡量对象在候选框区域上存在的概率,分数越高意味着图像窗口包含一个物体的可能性越大。过滤掉分数低的的候选框,因为它们最有可能属于背景。
(c)作者使用非极大值抑制消除重叠的候选框,得到未知对象的BBox。
(d)最后,得到已知和未知对象的BBOX。
Grouping and Ranking
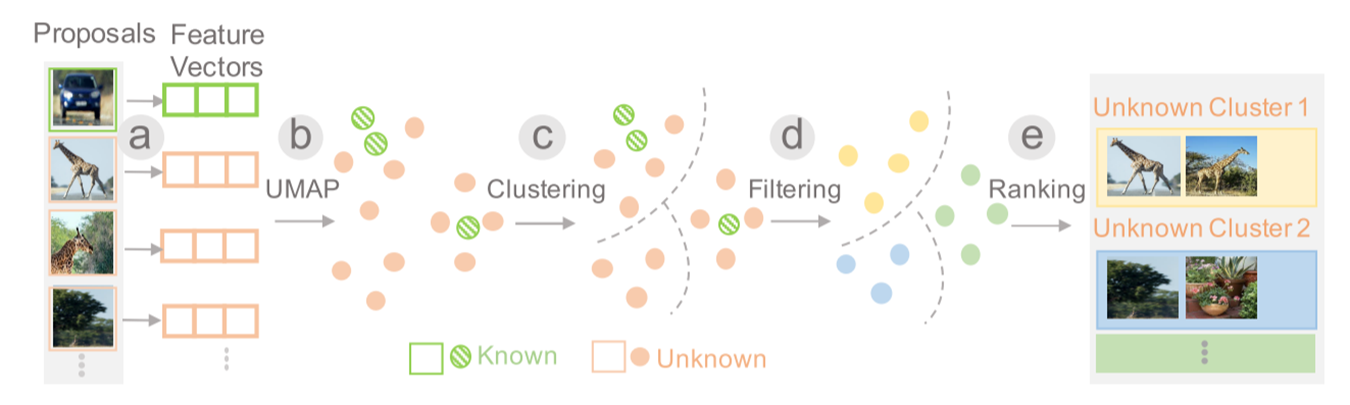
分组:
(a)首先获得每个候选框的特征向量,计算框中特征的平均值,得到高维特征表示
(b)然后使用UMAP将特征表示投影到2D隐空间
(c)根据候选框在2D隐空间中的表示对候选框进行K均值聚类
(d)将已知类的点移除
排序:
(e)根据不同的指标将这些类排序,以方便用户有效地识别重要的簇: 1.假阳率;2.熵; 3.最大置信度
Recommendation and Labeling
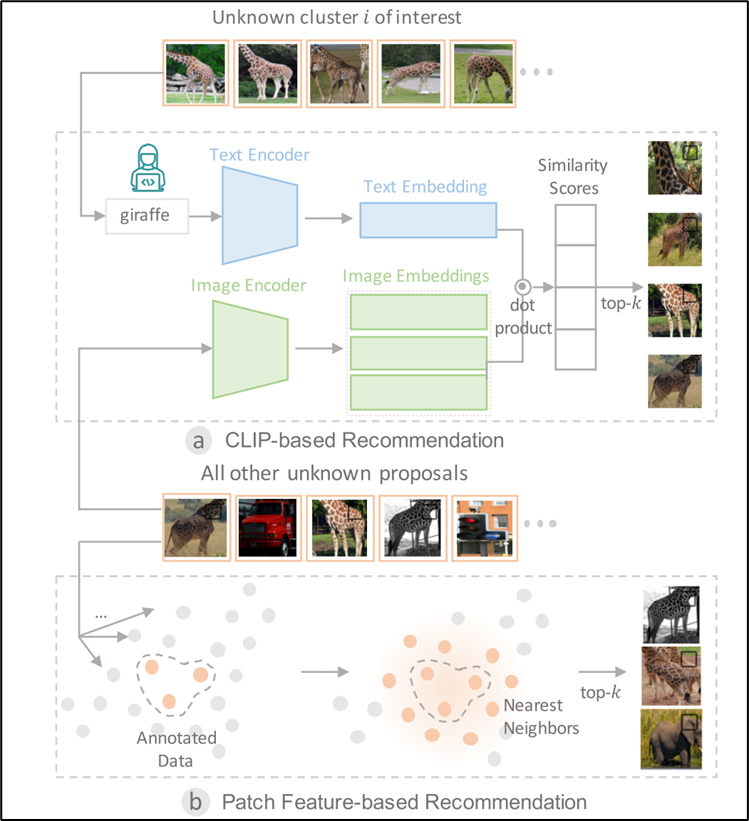
用户从簇中识别出一个未知类之后,作者引入了两种方法以加速注释过程,如图模块a和模块b所示。
第一个是CLIP-based Recommendation:使用Large Vision-language Model来找到可能属于目标未知类的候选框。具体来说,首先使用CLIP的Text Encoder来生成未知类的Text Embedding,并使用CLIP 的Image Encoder来生成未知类候选框的Image Embeddings。然后计算两者的余弦相似度,并选择相似度最高的前k个候选框,其中k默认设置为50。
第二个是Patch Feature-based Recommendation:在用户标注了一组未知类的候选框后,在2D投影的空间中找到与已注释候选框最近的k个候选框,因为相似的对象通常有相似的特征向量。具体来说就是在2D隐空间中找到每个注释候选框的k近邻。然后合并它们并删除重复项。
最终实现的效果是,基本找到整个数据集中与目前正在操作的未知类的对象,然后用户为这个类进行标注,使用作者他们提供的可视化工具,用户只需要输入该类的名字即可,不需要逐个打标签以及手动标注BBOX,这样大大减少了人工标注的成本。
Model Refinement
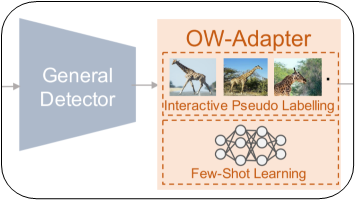
作者引入了一个轻量级分类器,执行少样本学习来对之后的未知对象进行分类。具体来说,作者训练了一个多层感知器(MLP),它将每个候选框的特征向量作为输入,并输出每个类的概率。用于训练MLP的训练数据包括属于已知类的所有框和未知类的新注释框。由于用户只为每个未知类注释了几个示例,因此已知类和未知类的注释数量是不平衡的,所以作者在训练过程中对未知注释进行了上采样。
在训练之后,作者将MLP插入到预先训练的目标检测器中,以扩展其处理未知对象的能力。在这种情况下,作者使用原来的分类头和MLP插件来获得每个候选框的预测。然后按如下方式对候选框进行分类,如果MLP插件将候选框分类为新添加的未知类之一,则将其预测为未知类,否则就使用原始分类头的预测结果。
可视化界面
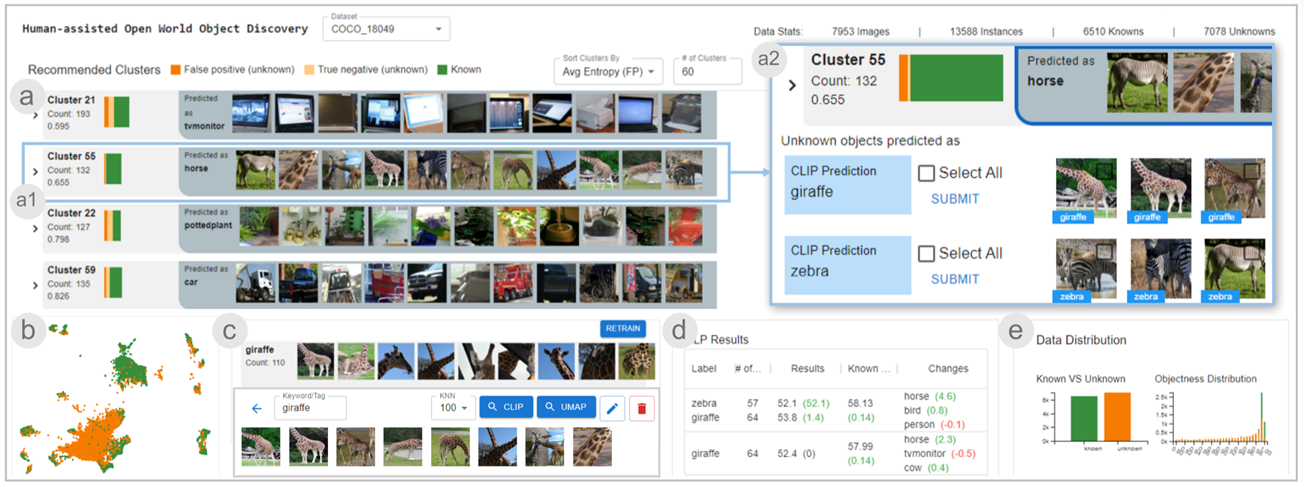
如图所示,作者设计开发了一个可视化分析系统,以提高未知对象的识别能力,以及减少的人力。该可视化分析系统主要包括5个模块:
(a)Clusters View
(a1)Recommended Clusters View 此视图可以总览所有未知对象的簇
(a2)Cluster Detail View 选择感兴趣的簇时,它的详细信息将在这个视图中显示
(b)Projection View 将候选框特征向量的2D投影可视化为散点图
(c)Annotation View 注释视图展示了一个新类的列表,其中逐行地显示了注释的示例,用户可以单击任何行来处理特定类的注释
(d)Model Performance View 模型性能视图展示了评估结果,该视图提供了模型性能的变化记录
(e)Statistic View 统计视图将候选框的objectness scores、大小、预测标签和置信度分数的分布可视化为条形图
示例分析
接下来以一个具体的示例来展示作者方法的执行流程
数据集
训练集:PASCAL VOC(18051张训练图像;20个对象类)
测试集:MSCOCO(4000张图像用于验证、10246张图像用于测试;80个对象类)
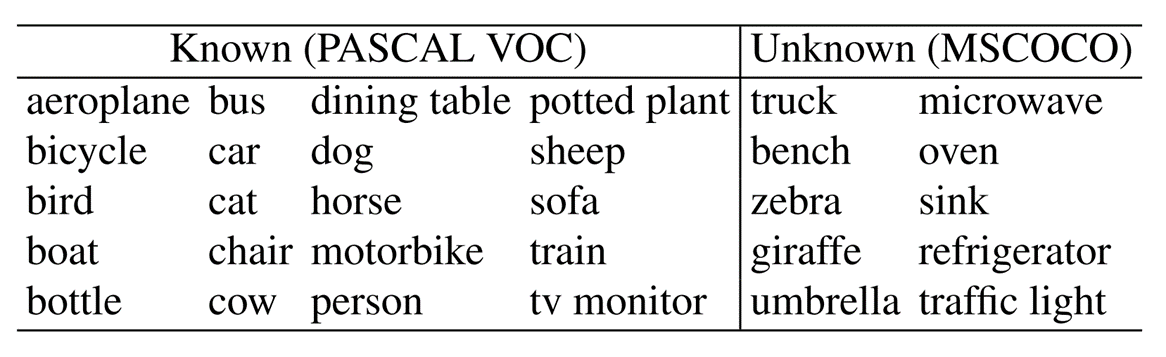
MSCOCO数据集包含80个对象类,其中20个与PASCAL VOC相同,如表格左边一列。另外60个类被认为是未知的,作者在实验中使用了其中的10个类当作未知类,如表格右边一列。
评估指标
根据F1分数、平均精度(mAP)以及两种指标每次迭代的变化。
具体流程
第一次迭代: 添加新的未知类“Giraffe”
对于得到的所有候选框,用户首先根据Statistic View中的条形图筛选掉objectness scores得分较低的候选框,并将剩余的候选框分组。通过基于中值熵值对聚类进行排序,选择分数最高的簇,如下图。

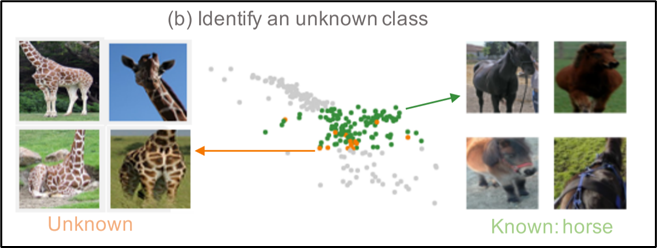
然后,用户使用Cluster Detail View和the Projection View查看簇的详细信息,如下图。用户观察到,大多数已知对象都是这个簇中的马,并且有一些未知类别的动物被预先训练的模型错误地分类为马。他还发现,大多数被错误分类的动物实际上是长颈鹿。用户决定添加一个名为“长颈鹿”的新类。
用户首先从簇中选择长颈鹿(N=8)作为起点,如下图中c1。然后,用户首先利用CLIP-based Recommendation得到相关候选框,如下图中c2。用户浏览了一遍候选框,删除了一些错误的候选框,并将剩余的候选框标记为长颈鹿(N=102)。随后,用户基于现有注释在patch feature space中搜索最近的样本,如下图中c3。搜索结果按相似性得分排序,用户再次浏览了这些候选框,并确定了CLIP遗漏的一些样本。他将这些候选框添加到注释中(N=110)。

然后训练MLP分类器,如下图。
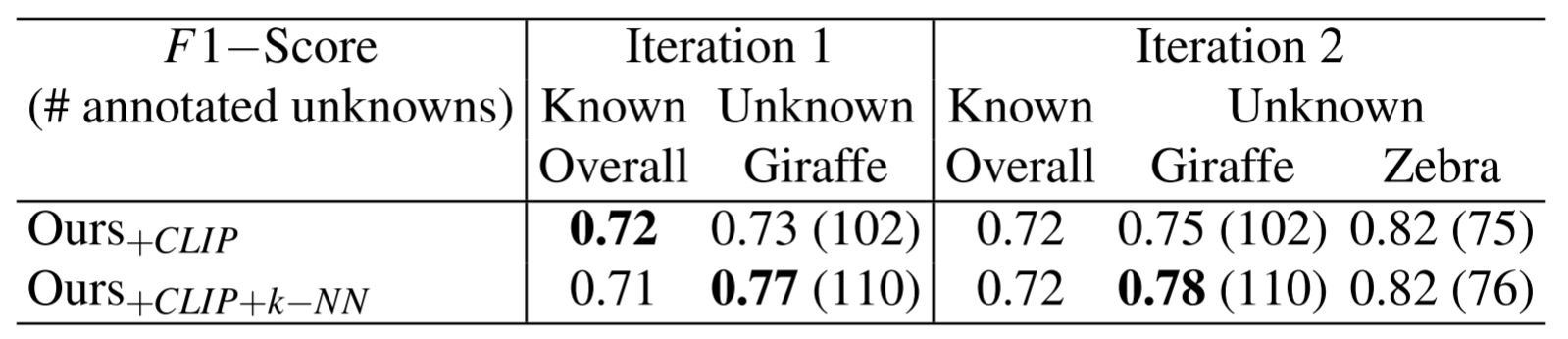
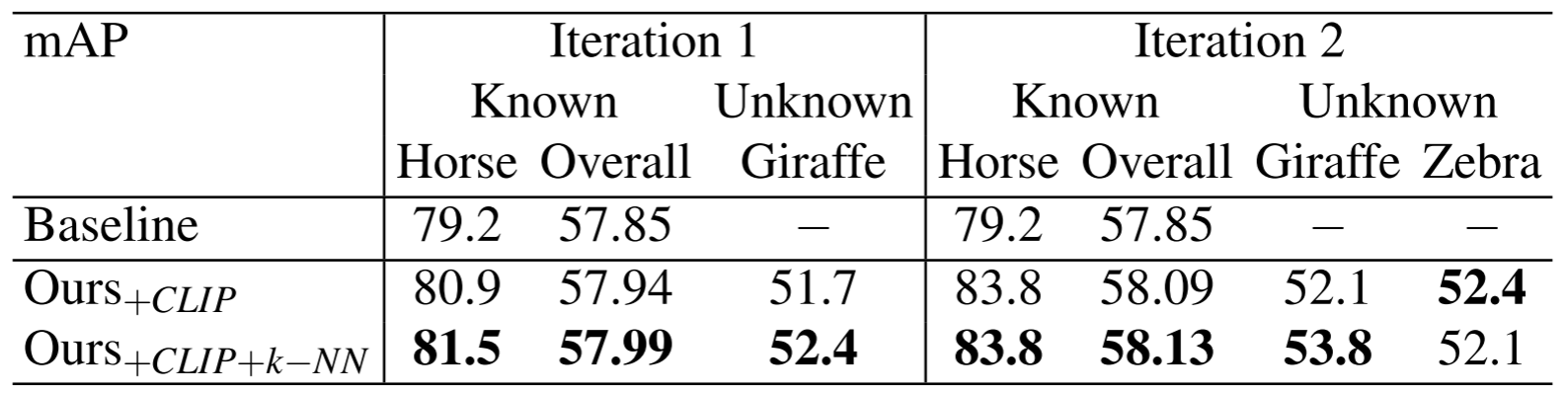
第一轮作者发现MLP可以较好地对长颈鹿进行分类,同时保留对已知类别分类的性能。此外,作者发现将CLIP和K-NN候选框结合使用比仅使用CLIP(0.73)更好的结果(0.77)。在对MLP的分类性能感到满意之后,作者将其插入到预训练的模型中,使用平均精度(mAP)评估性能,如第二张表所示。作者发现,已知类别的整体表现有所改善,特别是对马的识别相比baseline增加了+2.3。将结果与baseline进行比较,该模型现在可以对长颈鹿等新类别进行分类,性能显著提高(+52.4)。
第二次迭代:添加新的未知类“Zebra”。
- 第二轮作者将来自同一聚类的注释斑马添加到训练数据中,并重复前面的所有步骤。经过训练的分类器显示斑马的F1分数为(0.82),长颈鹿的F1分数为(0.78)。在将训练好的分类器集成到预先训练好的模型中之后,模型对马类的性能显示出显著的改善,从基线增加了(+4.6),从上一次迭代增加了(+2.3)。同时,该模型能够检测斑马和长颈鹿,性能分别提高了(+51.6)和(+53.8)。
第N次迭代
在重复该过程若干次迭代之后,最后能够识别10个最初未知的类(例如,卡车、大象、雨伞)。然后,作者将模型的性能与预训练模型和最先进的OWOD检测器进行了比较,如表格所示。作者发现他们的方法可以扩展预训练模型检测未知数的能力(+18.75),并略微提高已知类的性能(+0.36)。

总结
经过组会上的讨论,发现每年都有相似的标注系统相关论文发表,这已经不是一个创新的题目。同时深入论文中的算法,发现并没有使用新颖的算法或者是原创算法。得出的结论是这篇文章没有太大技术贡献,也没有太多讨论的价值,会汲取这次教训,下次论文选择上需要更加谨慎。
✉️ zjuvis@cad.zju.edu.cn